A sovereign AI automation platform concept
A centralised platform for AI automation could boost AI transformation and enable individuals and teams. But such platforms often depend heavily on foreign technology, laws and data centers located distantly. In this post, we explore the possibility of creating an enterprise-grade platform with full ownership and compliance while requiring low maintenance effort by maximising the use of managed services and open-source software.
Position of the low-code platforms in the AI-driven world
With the emergence of large language models (LLMs) and agentic solutions, the world is seeing a great push for vibe coding (developing custom code solutions in natural language with the help of AI agents) being accessible to everyone, including people far from professional development (known as citizen developers). While this approach is valid, low-code and no-code platforms are not losing positions, because they cover important things beyond the application code itself. Platforms, such as Microsoft Power Platform or n8n, abstract away unwanted complications for citizen developers:
- Hosting and scaling are handled seamlessly by the platform, without any need to understand technologies and concepts such as containers, HTTP servers, horizontal scaling and load balancing.
- Many security concerns are addressed at the system level, excluding the possibility of falling into the most common pitfalls. This includes security patches and vulnerability fixes that the platform gets regularly, and security policies enforced on the organisation level.
- Pre-existing building blocks and integrations remove the need to maintain and understand big chunks of code.
- Administrators benefit from easier governance, auditing and access control.
- The same vibe-coding-like experience is available, so we don’t need to find a compromise and can benefit from both worlds.
- At last, citizen developers get a much more accessible experience with visual representation of the application and flows in it instead of actual code, functions and modules, which makes both development and debugging way simpler.
Of course, this comes with a cost, including:
- Functional limitations — not everything is feasible or meaningful with low-code tools, and it’s a subject of the platform provider’s vision and capabilities, not only the developer’s intention.
- Performance overhead — many layers of abstraction are costly, and you cannot expect a possibility to serve millions of people with a visually built workflow. All these points apply to the agentic AI solution development, which can be done with both custom code and low-code tools.
The EU digital sovereignty problem
The major issue with low-code platforms is that most of them are heavily reliant on US tech, and even if not, they are hosted on US cloud hyperscaler infrastructure, which makes them subject to US laws. It’s a problem due to two US pieces of law:
The US Cloud Act, which may legally force a US-based provider with a data center in Frankfurt to hand over European customer data stored on that German server.
Foreign Intelligence Surveillance Act (FISA) and Reforming Intelligence and Securing America Act (RISAA), which allows the targeting of non-US persons located outside the US for foreign intelligence purposes, without a court decision, and forces service providers to leave a possibility to secretly support US authorities.
So while placing data within EU boundaries formally complies with GDPR, there is no full ownership of data if it’s placed on US-provided servers. This applies to SaaS, PaaS and LLMs as well in many cases. For example, n8n cloud, although being developed by a European company, is hosted on Azure datacenters in Germany.
But even if we forget about legal compliance, there is a big sovereignty issue for smaller countries like Finland. Most of the Finnish public and private services, including transport and healthcare, are hosted in one of the big 3 hyperscaler data centers outside of Finland. The only local data center — GCP in Hamina — is not fully independent and relies heavily on global services and external connectivity. The risk here is a nationwide outage in the case of another cable cut-off (which is not a rare occurrence nowadays) or a global service issue (see recent AWS and Cloudflare cases).
To ensure operation continuity and true ownership, local services should become one of, if not the most, prioritised ways to go.
To know more about the problem, check out this talk by Michael Samarin at DevOps Finland (starts at 30:13).
Local services should become one of, if not the most, prioritised ways to go to ensure operation continuity and true ownership,
A sovereign AI agents platform concept
Luckily, the options are available. Here, we consider a Finland-oriented solution that scales easily to other countries. The great thing about n8n is not only that it’s a powerful AI automation platform with agent-building capabilities, but it also has an option for self-deployment. In our concept of a fully sovereign AI platform, we consider 3 main components:
- Cloud infrastructure with European ownership and location in Finland. Our choice is UpCloud, although it could be any alternative, such as ScaleWay (although there are no servers in Finland as of Q1/2026) or an on-premises deployment.
- The platform itself, n8n is a natural choice considering its licensing model, European origins and popularity.
- AI hosting solution. Here, we would need GPU servers to execute the inference (UpCloud has them) and a runtime, which is reliable and scalable. For the latter, we have chosen vLLM, a powerful enterprise-grade open-source engine for serving any of the open-source LLMs through a well-known OpenAI-compatible API. An alternative to this could be Ollama, which is a more user-friendly but simple engine.
- With these foundations, along with the possibly supporting components like observability setup and enterprise data access infrastructure, a fully standalone, scalable and production-ready platform could be created.
Next, we consider architecture in detail.
Application plane architecture
The architecture assumes that all applications are hosted on Kubernetes to achieve scalability and a consistent deployment approach. At the same time, managed services are used outside of Kubernetes to simplify maintenance when possible.
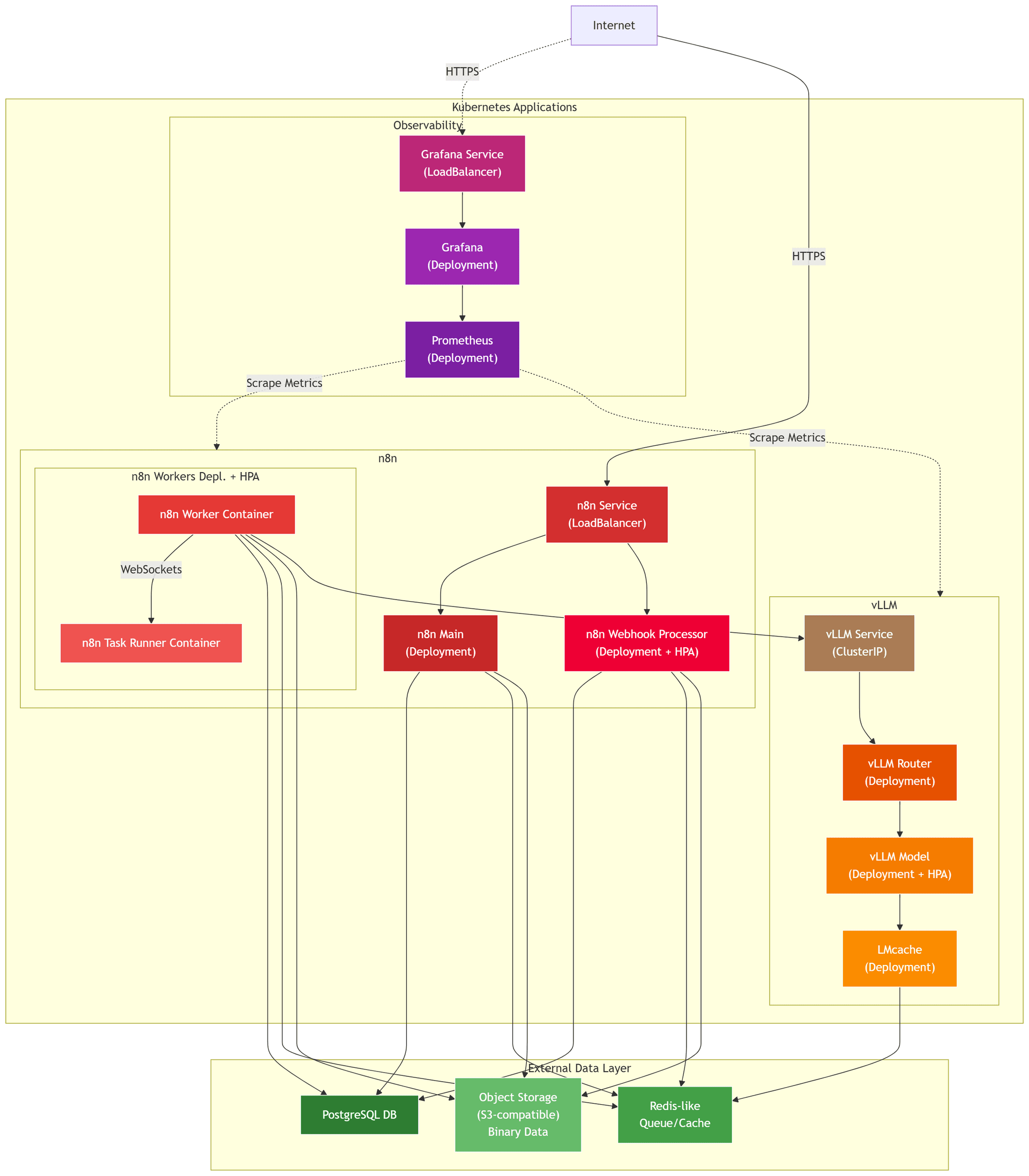
There are 3 main sets of applications suggested for deployment: n8n in the most distributed setup, vLLM with both router and model deployments, optional observability setup with metrics collection, dashboards and alerts. In the illustration, the architecture is described. Note that some simplification is applied: for example, some services and persistent volumes are left out.
Scalable n8n setup
Deployment of n8n in the production enterprise environment consists of several components:
The main instance, which serves a graphical interface and API, and controls the configuration. There is an option for a multi-main setup for high availability.
Workers which are executing workflows. They come as a separate deployment for simple horizontal scaling: more instances, more workflows the system can execute at the same time. All workers have two components:
- The worker, which is listening to the jobs queue and executing most of the workflow nodes.
- Task runner that connects to the worker process via WebSocket and executes only custom code nodes [JavaScript or Python], which is done for better security.
Webhook processors, which only listen for incoming webhook requests and place the associated workflow invocation into the queue. With this separation of concerns, the system can handle large amounts of requests without affecting the user interface performance. Comes with an option for horizontal scalability.
All components except task runners have to connect to 3 managed services:
- PostgreSQL database which stores the workflows, invocation history, connector credentials, system configuration, etc.
- A Redis-compatible KV database, which only serves as a queue for distributed workflow execution.
- S3-compatible object storage, which is used as a storage for binary files for the workflows that need them.
Some AI agents, especially RAG solutions, would also require vector storage for embeddings. It’s not a part of the base architecture, but could be considered as an optional component to be connected with the workers.
While the most-distributed and complex setup of n8n comes with some performance overhead and configuration complexity, we still recommend going with it right from the start. It would provide a better understanding of the production environment performance operations, since a single instance n8n is proven to be not sufficient for enterprise-wide adoption due to scalability issues.
Self-hosted AI models
vLLM setup is based on the reference production design built by the vLLM team. It mainly consists of:
- Router, which directs requests to appropriate LLM backends to maximise KV cache reuse.
- Backend model serving engine, where different deployments may serve different models and all of them are horizontally scalable.
- LMCache server, which helps to move large KV caches from GPU memory to shared storage, enabling more potential KV cache hits, especially for scaled setups. In our setup, we suggest using Redis as a storage backend to LMCache.
With the distributed and shared-cache-enabled setup, production vLLM deployment could provide an enterprise-grade performance, not achievable by other solutions, like Ollama.
Observability
Both n8n and vLLM applications support exporting metrics in Prometheus format. While n8n itself does provide some monitoring capabilities, they are quite primitive and force us to use different tools for different applications, which is far from optimal. Thus, our architecture suggests deploying Prometheus, Grafana and any other supporting tool, like Alertmanager, on the same Kubernetes cluster. Alternatively, an org-wide observability platform could be used, either on top of the same Prometheus but on a separate cluster, or with the use of some other tool, like Datadog, log streaming to which n8n does support.
Infrastructure plane architecture
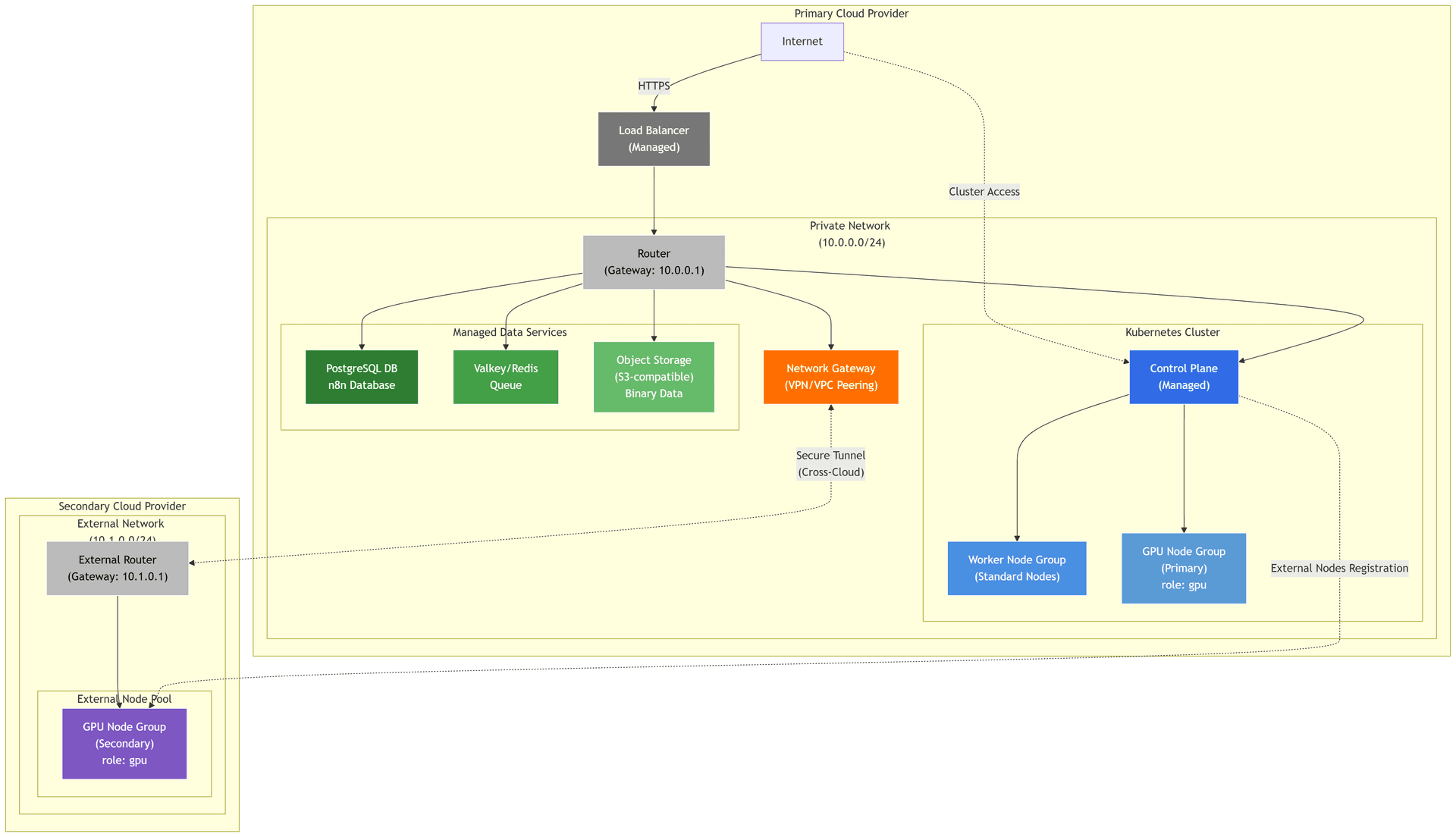
Cloud architecture, illustrated above, assumes UpCloud is used as a cloud provider. But a similar setup could be achieved on most of the other platforms as well. The use of managed services is maximised, including:
- Kubernetes with two or more managed Node pools.
- Load balancer.
- PostgreSQL server.
- Object storage, which is S3-compatible in UpCloud.
- Valkey, an open-source, BSD-licensed fork of Redis.
- A number of foundational services, such as a network with a router, and disks for persistent storage.
A single major difficulty we experienced with UpCloud in Q1/2026 is the GPU servers: the GPU infrastructure is still only being built, servers only exist in Helsinki and are often not available due to the high interest. To mitigate that and also to ensure additional scalability and high availability, we suggest deploying reserve GPU nodes with a different cloud provider. In this case, a managed VPN gateway is to be deployed on the UpCloud side, connecting external GPU servers to the rest of the infrastructure. Then, virtual machines with attached GPUs are onboarded to Kubernetes as nodes. This is possible thanks to UpCloud’s unrestricted managed Kubernetes control plane.
Our experience from the proof of concept
Proof-of-concept deployment of the described architecture has been used by us for internal needs. Deployment showed its capability of achieving enterprise-grade performance and robust scalability. Next, we describe a few things to keep in mind.
GPU server availability on UpCloud, just like noted, is still far from perfect, although the expansion project is already planned for Q2/2026. In our PoC, we used both GPU servers from UpCloud and external servers hosted on Azure. Onboarding external nodes to the managed Kubernetes is not straightforward, but achievable, which we plan to cover in the following blog posts.
vLLM is capable of serving most of the open-source models, from small to extra-large. But the models have different capabilities and behave differently in combination with n8n. One of the pain points is the tools calling from the built-in n8n AI Agent node. It adds its own wrapping and formatting to the tools calling prompts, which then go through the OpenAI-like API server, then transformed to the format appropriate to the model, and the model may have different capabilities, such as parallel tools calling or tool identification (some reference is available in vLLM documentation). As a result, errors accumulate, and the workflow stops working. Selecting the right model is out of the scope of this post, but to our experience, models based on Llama architecture, such as for example Hermes 3 or Llama 4, work seamlessly. Kimi and DeepSeek models work as well. However, we experienced major troubles making tool calls work with the Mistral 7B model, and all limitations explained in the vLLM documentation regarding tool calling applied. We expect better suitability for newer Mistral family models.
A major benefit of n8n comes from the rich set of data connectors. But in the enterprise environment, securing a connection to the proprietary data is important, which may affect the architecture. There could be a need for additional VPN gateways set up to connect to on-premises or other provider-hosted data sources.
After the deployment
Provisioning the platform is only one part of the enablement, especially if the target goal to a change towards citizen development. Well-defined governance model is essential for the beginning of the transformation journey and includes, among other things:
- Policies and standards, which adjust the general technical foundation into a safe and compliant environment. Examples could be allowed and disallowed system connections in n8n, approval processes for production deployment.
- Portfolio management, which increases visibility into what is being built, for what, and who the owner is. In addition to organising workflows in projects in n8n, there is a need to collect additional data on intent and ownership.
- Monitoring, to ensure both resource and cost efficiency and operational continuity. The observability setup, suggested in this post, serves as a foundation for this.
- Community and reusable assets, which encourage collaboration, knowledge sharing and prevent reinventing the wheel.
Providing access to tools is only the beginning. Unlocking actual productivity potential is a result of a well-defined and controlled transformation program.
Conclusion
Sovereignty is a way to true ownership and guaranteed operational continuity. Our proof of concept shows how to achieve it for AI citizen development platforms and AI models. The same approach could be applied to other SaaS, such as office suites, analytics platforms, etc.
In the next blog posts, we are going to talk about a multi-cloud setup for GPU infrastructure, several use cases for the described architecture, and extensive throughput and latency tests.
Get in touch to discuss sovereign platforms and citizen development ->
 Anton AndreevTech Principal
Anton AndreevTech Principal



